Before LLM
Until 2017, most NMT models, including the one that powered Google Translate, were recurrent neural networks. RNNs use Long Short-Term Memory (LSTM) cells to factor word order into their calculations.1
In 2017, a landmark paper titled “Attention Is All You Need” changed the way data scientists approach NMT and other NLP tasks. That paper proposed a better way to process language based on transformer models that eschew LSTMs and use neural attention mechanisms to model the context in which words are used.
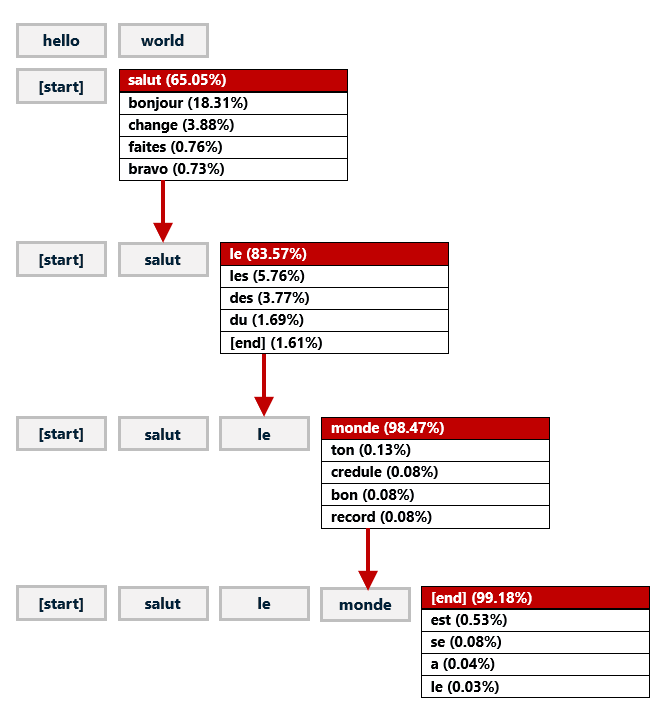


BERT (Bidirectional Encoder Representations from Transformers)
BERT isn’t generally useful by itself, but it can be fine-tuned to perform specific tasks such as sentiment analysis or question answering. Fine-tuning is accomplished by further training the pre-trained model with task-specific samples at a reduced learning rate, and it is much less expensive and time-consuming than training BERT from scratch.
Aside from the fact that it was trained with a huge volume of text, the key to BERT’s ability to understand human language is an innovation known as Masked Language Modeling. MLM turns a large corpus of text into a training ground for learning the structure of a language. When BERT models are pretrained, a specified percentage of the words in each batch of text – usually 15% – are randomly removed or “masked” so the model can learn to predict the missing words from the words around them. Unidirectional models look at the text to the left or the text to the right and attempt to predict what the missing word should be. MLM uses text on the left and right to inform its decisions.
GPT (Generative Pretrained Transformer)
Unlike BERT, GPT models can perform certain NLP tasks such as text translation and question-answering without fine-tuning, a feat known as zero-shot or few-shot learning. … ChatGPT is a fine-tuned version of GPT-3.5, which itself is a fined-tuned version of GPT-3. At its heart, ChatGPT is a transformer encoder-decoder that responds to prompts by iteratively predicting the first word in the response, then the second word, and so on.
The entire body of knowledge present on the Internet in September 2021 (and then some) was baked into those 175 billion parameters during training. It’s akin to you answering a question off the top of your head rather than reaching for your phone and Googling for an answer. When Microsoft incorporated GPT-4 into Bing, they added a separate layer providing Internet access.
Applications
If you do understand this, then you have to ask, well, where are LLMs useful? Where is it useful to have automated undergraduates, or automated interns, who can repeat a pattern, that you might have to check?2
LangChain
…it makes it easy to call OpenAI’s GPT, say, a dozen times in a loop to answer a single question, and mix in queries to Wikipedia and other databases. The clever bit is that, using LangChain, you intercept GPT when it starts a line with “Act:” and then you go and do that action for it, feeding the results back in as an “Observation” line so that it can “think” what to do next.3
Fine-Tuning
How to generate training data https://news.ycombinator.com/item?id=36070533
- make your own RLHF dataset - like OpenAI and Open Assistant
- exfiltrate data from a bigger/better LLM - Vicuna & family
- use your pre-trained LLM to generate RLAIF data, no leeching - ConstitutionalAI, based on a set of rules instead of labelling examples
How to use it with vector store https://news.ycombinator.com/item?id=36070797
I would strongly recommend against fine-tuning over a set of documents as this is a very lossy information system retrieval system. LLMs are not well suited for information retrieval like databases and search engines.
The applications of fine-tuning that we are seeing have a lot of success is making completion models like LLaMA or original GPT3 become prompt-able. In essence, prompt-tuning or instruction-tuning. That is, giving it the ability to respond with a user prompt, llm output chat interface.
Vector databases, for now, are a great way to store mappings of embeddings of documents with the documents themselves for relevant-document information retrieval.
Using vector store with fine-tuning https://news.ycombinator.com/item?id=36079880
I want the user to be able to ask technical questions about a set of documents, then the user should retrieve a summary-answer from those documents along with a source.
I first need to fine-tune GPT4 so it better understands the niche-specific technical questions, the words used, etc. I could ask the fine-tuned model questions, but it won’t really know from where it got the information. Without fine-tuning the summarized answer will suffer, or it will pull out the wrong papers.
Then I need to use a vector database to store the technical papers for the model to access; now I can ask questions, get a decent answer, and will have access to the sources.
AI Safety
Human in the Loop
The danger of using MTurk as a “human in the loop” to fact-check LLM responses4:
It is tempting to rely on crowdsourcing to validate LLM outputs or to create human gold-standard data for comparison. But what if crowd workers themselves are using LLMs, e.g., in order to increase their productivity, and thus their income, on crowdsourcing platforms?
DeepSeek
Footnotes
-
https://www.atmosera.com/ai/understanding-chatgpt/ “Understanding ChatGPT” ↩
-
https://www.ben-evans.com/benedictevans/2023/7/2/working-with-ai “AI and the automation of work” ↩
-
https://interconnected.org/home/2023/03/16/singularity “The surprising ease and effectiveness of AI in a loop” ↩
-
https://techcrunch.com/2023/06/14/mechanical-turk-workers-are-using-ai-to-automate-being-human/ “Mechanical Turk workers are using AI to automate being human” ↩